

In late 2025, Cloudflare launched something the SEO and publishing world had been asking for: a machine-readable way to tell AI crawlers exactly what they’re allowed to do with your content. Not just whether they can crawl it — but whether they can train on it, use it for real-time AI answers, or index it for traditional search. They called it Content Signals.
Then Google quietly declined to play along.
Here’s what happened, why it matters, and what you should actually do about it — including a free tool to generate your own Content Signals directives in about 30 seconds.
 What Content Signals actually are
What Content Signals actually are
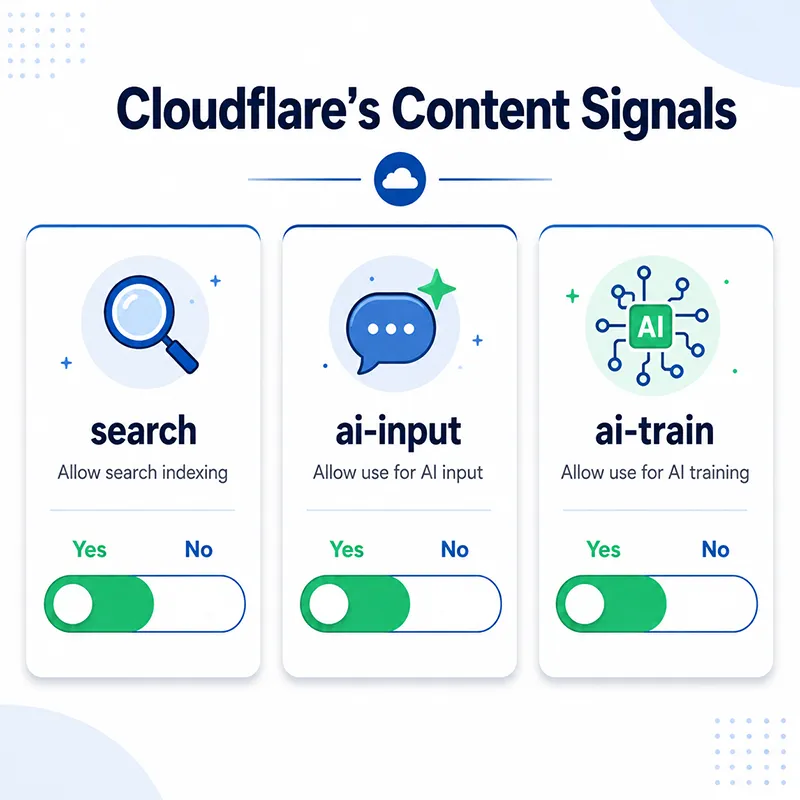
Cloudflare’s Content Signals add a new directive to your robots.txt file. Where the traditional robots.txt only controls whether a bot can access your content, Content Signals go a step further — they declare what a bot is allowed to do with your content once it has it.
There are three signals:
- search — permission to build a traditional search index and return links and excerpts. Explicitly excludes AI-generated search summaries.
- ai-input — permission to use your content as real-time input for AI-powered answers: retrieval augmented generation (RAG), grounding, AI Overviews, and similar.
- ai-train — permission to use your content to train or fine-tune AI models.
In your robots.txt, the directive looks like this:
User-Agent: *
Content-Signal: ai-train=no, search=yes, ai-input=no
Allow: /That single line says: index me for search, but don’t use my content to power AI answers or train your models. It’s a meaningful distinction that traditional robots.txt simply can’t make.
Cloudflare released the specification under a CC0 license — meaning any platform can adopt it — and they’re pushing for it to become a broader industry standard through the IETF (Internet Engineering Task Force)’s AIPREF (AI Preferences) working group. They also automatically added it to the managed robots.txt files of millions of their customer sites.
So far, so sensible.
Where Google stands — and why it matters
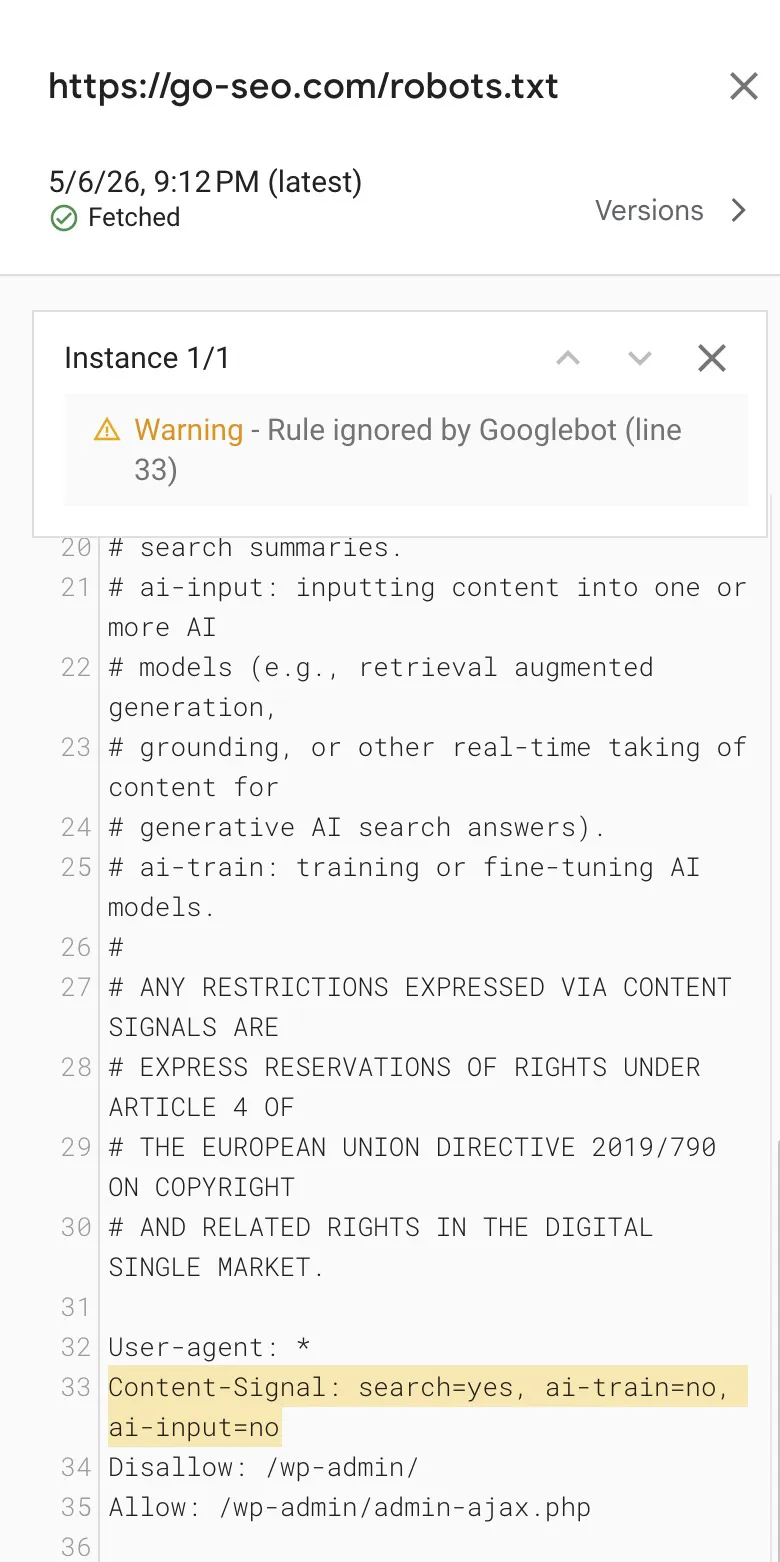
Here’s where it gets interesting. Cloudflare CEO Matthew Prince confirmed that Google was given advance notice of the Content Signals specification before launch. Google’s response? Silence. No commitment to honor it.
I know this firsthand — I’ve already added Content Signals to go-seo.com’s robots.txt. Google Search Console’s response was immediate and unambiguous: ‘Rule ignored by Googlebot,’ applied directly to the Content-Signal line. That’s not a parsing warning. That’s Google’s own tooling confirming, in plain language, that the directive is being disregarded.
Cloudflare has stated they’ve observed no impact on crawl rates from these warnings — but that’s almost beside the point. Google is signaling, through its own tooling, that it considers the directive non-standard and outside the scope of what it recognizes.
This isn’t Google saying the idea is wrong. It’s Google choosing to operate under its own terms, on its own timeline. Given that Google controls the largest AI-powered search feature on the web — AI Overviews — their non-participation is significant. If you set ai-input=no hoping to stay out of AI Overviews, there’s currently no indication Google is honoring that request.
Other major AI crawlers? Also not committed. Compliance across the board is voluntary, and robots.txt has always been a preference file — not a technical enforcement mechanism.
Does that mean Content Signals are useless?
Not quite. A few things are worth keeping in mind.
Signals vs. enforcement are two different problems. Cloudflare themselves are explicit about this: Content Signals express your preferences; their AI Crawl Control feature — which operates at the WAF (Web Application Firewall) level — is what actually enforces them. If you want to technically block a crawler, you need WAF rules, not robots.txt. But establishing your stated position in a machine-readable, standardized way matters as the legal and regulatory environment evolves.
Some crawlers do pay attention. Not all AI crawlers are Google. Smaller and newer AI platforms may be more likely to honor explicit signals as the standard matures. Setting your position now means you’re on record when compliance becomes more expected — or legally relevant.
The spec is moving toward standardization. The IETF’s AIPREF working group is actively developing a formal standard for AI content usage preferences. Cloudflare’s Content Signals are explicitly designed to align with wherever that lands. Early adopters aren’t wasting their time — they’re getting familiar with the syntax before it becomes required.
It’s the clearest “no” available today. Prior to Content Signals, there was no way to say “index me for search but not for AI Overviews” in your robots.txt. You either blocked a crawler entirely — losing search traffic in the process — or you let them in with no conditions. The three-signal system solves that. Even if enforcement is spotty, the intent is now on record.
What you should actually do
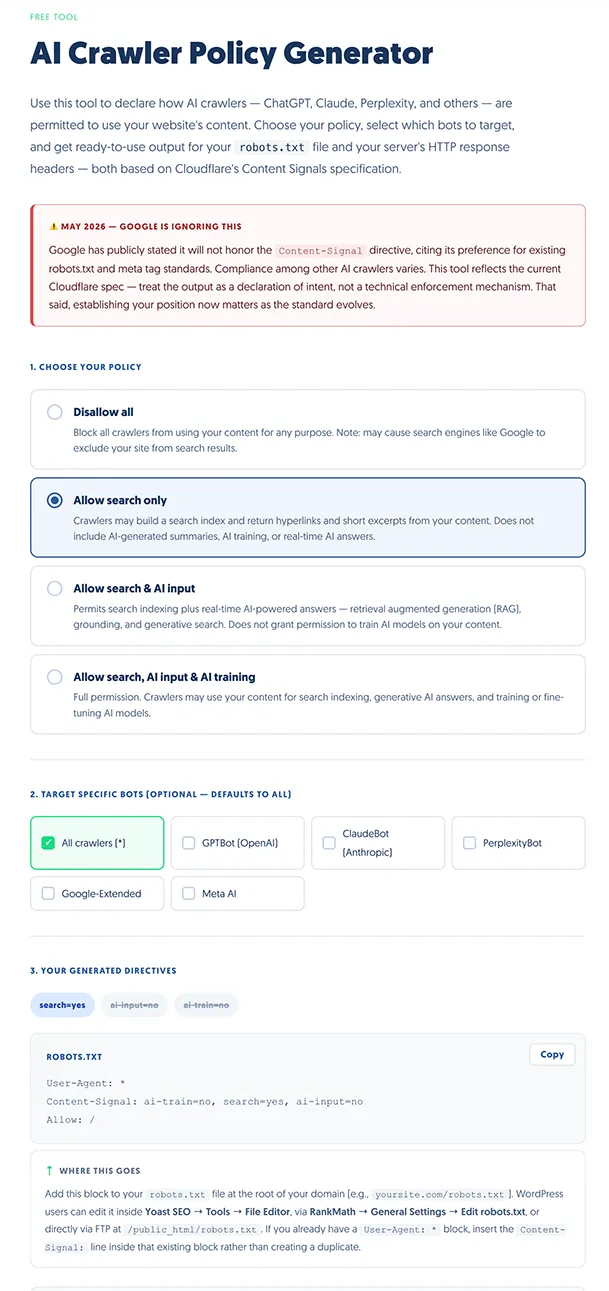
My recommendation for most small and mid-sized businesses: implement Content Signals, pair them with targeted bot controls if you’re on Cloudflare, and don’t expect them to be a complete solution on their own.
Think of it the same way you think about a well-structured privacy policy. It doesn’t stop bad actors, but it establishes your legal and ethical position. In a landscape where AI training data is increasingly contentious — and where litigation around it is actively happening — having a documented, machine-readable statement of your content preferences has real value.
For most sites, I’d suggest starting with search=yes, ai-input=no, ai-train=no and revisiting ai-input once you have data on how AI-powered search is driving traffic to your site. For businesses actively trying to show up in AI-generated answers as part of a GEO strategy, ai-input=yes may be the right call — you want those crawlers ingesting your content for real-time retrieval.
Use the tool illustrated at left to generate your directives in about 30 seconds. It also gives you the HTTP header version, which works at the server level rather than just in robots.txt. Just click the big green button to load the tool.
The bigger picture
What Cloudflare has done with Content Signals is name a problem that the web has had for three years: there is no clear, standardized way for content owners to express granular preferences about AI use. The traditional robots.txt was built for a world where crawling and indexing were the same thing. They’re not anymore.
The fact that Google isn’t honoring the standard yet doesn’t invalidate the standard — it just tells you where Google’s interests currently lie. That’s useful information on its own.
If you’re managing a site that produces original content — a blog, a service business, a local brand — you’re already a participant in a system that is actively monetizing your words without a clear consent mechanism. Content Signals won’t fix that overnight. But establishing your position clearly, in a format that’s moving toward standardization, is the right move.
I’ve been watching search evolve since 2007. Every major shift — from PageRank to mobile-first to AI-generated answers — has rewarded the people who moved early and stayed informed. This one is no different.
If you’re not sure which policy is right for your business, or how this intersects with your broader GEO strategy, let’s talk.
Frequently asked questions
What is “Cloudflare’s Content Signals”?
“Content Signals” is a specification developed by Cloudflare that adds machine-readable directives to your robots.txt file. Unlike traditional robots.txt directives that only control whether a bot can access your content, Content Signals declare what a crawler is permitted to do with your content after accessing it — including whether it can use it for traditional search indexing, AI-powered answers, or AI model training.
Is Google honoring Content Signals?
Not currently. Google has not committed to honoring the Content-Signal directive. Cloudflare CEO Matthew Prince confirmed that Google was notified in advance of the launch but did not indicate it would respect the new signals. Google Search Console may flag the directive with a “Rule ignored by Googlebot” warning, though Cloudflare has noted no observed impact on crawl rates. Compliance across all AI platforms remains voluntary.
Will adding Content Signals hurt my Google rankings?
According to Cloudflare, implementing Content Signals has not been shown to impact crawl rates or SEO performance. Google Search Console may display a “Syntax not understood” warning for the directive, but Cloudflare reports this warning has no observed effect on how Google crawls or indexes your site.
What is the difference between the robots.txt directive and the HTTP Content-Signal header?
The robots.txt directive expresses your preferences to crawlers when they read your robots.txt file — typically before or during a crawl. The HTTP Content-Signal header is sent at the server level with every page response, broadcasting your policy on each individual request regardless of whether a crawler has read your robots.txt. Using both together provides the most comprehensive coverage.
Should I set ai-input to yes or no?
It depends on your goals. If you want your content cited in AI-generated answers from platforms like ChatGPT, Perplexity, or Google AI Overviews — which can drive brand visibility and qualified traffic — setting ai-input=yes supports that. If your priority is protecting your content from being summarized in ways that reduce direct traffic, ai-input=no expresses that preference, though enforcement is currently voluntary and crawler-dependent.
Does robots.txt legally prevent AI companies from using my content?
No. The robots.txt file, including Content Signals directives, is a statement of preference — not a legal enforcement mechanism or technical access control. Compliance is voluntary. Some AI companies may honor it; others may not. For stronger enforcement, Cloudflare’s AI Crawl Control (which operates at the WAF level) provides technical blocking rather than signaling. Legal protections for content ownership are a separate and still-evolving matter.





